简介
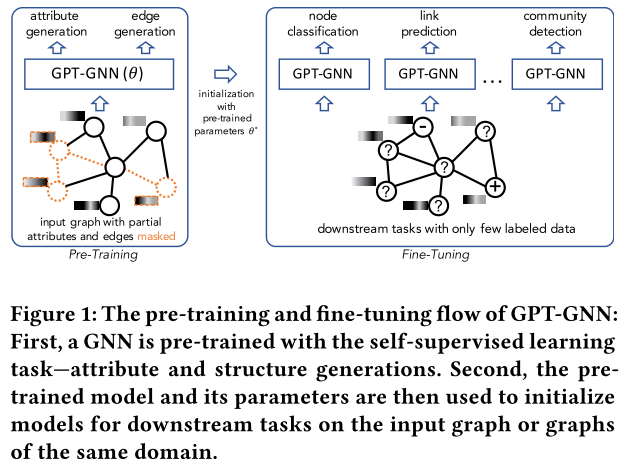
由于图学习的下游任务往往标签数据很稀缺,一个有效减少标注代价的方式就是先使用无监督学习预训练一个图神经网络模型,然后使用少量标注数据将该模型迁移到下游任务上。在该论文中,作者提出GPT-GNN框架,其通过生成预训练的方式来初始化一个图神经网络模型。GPT-GNN 引入一个自监督属性网络生成任务来预训练一个图神经网络,这样它可以捕捉到图的结构和语义性质。该论文将图生成的似然概率分解为两个部分:1)属性生成和2)边生成。在生成过程中,通过建模这个部分,GPT-GNN捕捉到节点属性和图结构之间的内在依赖。另外,作者提出了一种高效的策略,通过对节点划分为属性生成节点和边生成节点,可以同时计算每个节点的属性生成损失函数和边生成函数,并且只需要训练一次图神经网络。另外,GPT-GNN可以处理大规模的网络,通过子图采样和自适应的嵌入队列来负采样。
方法
分解属性网络生成
- 给定一个输入网络$G = (V, E, X)$ 和一个图神经网络模型 $f_\theta$ ,我们建模该图的似然概率 $p(G, \theta)$:
其中$\pi$是节点的所有排列。
给定一个排列顺序,我们将自回归地分解对数似然,也就是迭代的生成每一节点,如下:
一种简单的方法是假设$X_i$ 和 $E_i$ 之间是独立的:
但这种简单地分解并能为图神经网络的预训练提供有信息的指引,因此,作者提出依赖察觉机制,用于属性网络生成过程:
其中$E_i$表示与节点$i$相连的边。$o$ 代表观察到的边集合,$\neg o$代表未观察到的边。
下面是属性网络生成过程的一个例子:
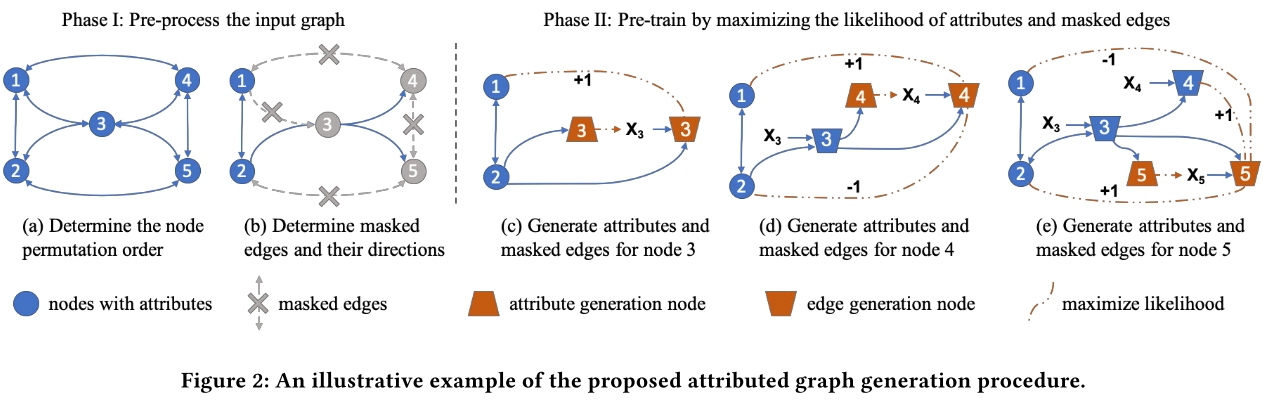
(a)首先,我们决定输入网络节点的排列顺序$\pi$。(b)我们随机选择目标节点的一部分边作为被观察到的边$E_{i,o}$,将目标节点剩下的边作为被遮掩边$E_{i,\neg o}$。删除掉图中的遮掩边。(c)将每一个节点划分到属性生成节点或边生成节点,以防止信息泄露。(d) 经历过预处理后,使用修改过的邻接矩阵来节点3,4,5的表示。最后如(d)-(e)所示,我们通过属性生成任务和被遮掩边生成任务来预训练图神经网络。
属性生成损失函数如下:
遮掩边生成损失函数如下:
算法流程图如下所示:
